Scientific Grid-Computing an der TU Wien
An der TU Wien gibt es 250 PCs, die - gekoppelt über ein Netzwerk und mit
entsprechender Software ausgestattet - einen "virtuellen Supercomputer"
bilden, dessen theoretische Maximalleistung im Bereich einiger Tflop/s
(Billionen Gleitpunkt-Rechenoperationen pro Sekunde) liegt. Diese beachtliche
Rechenleistung wurde bis vor kurzem überhaupt nicht genutzt, ja nicht einmal
zur Kenntnis genommen. Dieser Artikel soll potentielle Interessenten -
wissenschaftliche Arbeitsgruppen wie auch einzelne Mitarbeiter der TU Wien
- auf die Möglichkeit aufmerksam machen, diese bisher ungenutzten Rechenkapazitäten
für Applikationen mit geringen Speicher- und Kommunikationsanforderungen
in Verwendung zu nehmen.
Scientific Computing
Das Verständnis von Phänomenen und Prozessen aus Natur- und Ingenieurwissenschaften
stützt sich heute nicht mehr allein auf theoretische Betrachtungen und
Experimente, sondern zunehmend auch auf Berechnungen und Simulationen.
Ausgelöst vom exponentiellen Wachstum der Rechenleistung und des verfügbaren
Speichers der immer preisgünstiger werdenden Computersysteme nimmt die
Bedeutung des multidisziplinären Wissenschaftszweigs "Computational Science
and Engineering" für die Universitäten wie auch für die Industrie rasant
zu. Das kommt nicht zuletzt in der Festschreibung dieses Gebiets als fakultätsübergreifendes
Kompetenzfeld im aktuellen Entwurf des Entwicklungsplans der TU Wien zum
Ausdruck.
"Computational Science and Engineering" bedarf oft sehr rechenintensiver
Simulationen, wobei in manchen Fällen der Ressourcen-Bedarf alle Möglichkeiten
der aktuell verfügbaren Hardware- und Software-Technik überschreitet. Dementsprechend
hängt die Lösbarkeit solcher Problemstellungen sehr oft davon ab, ob man
die benötigte Rechenzeit in einen noch akzeptablen Bereich bringen kann.
Jene Faktoren, die dabei eine Rolle spielen und in geeigneter Weise beeinflusst
werden müssen, kann man der etwas umgeformten Leistungsformel der Physik
"Leistung = Arbeit / Zeit", nämlich

sofort entnehmen. Die Lösbarkeit schwieriger Probleme des Scientific Computing
hängt dementsprechend von der verfügbaren Hardware, den verwendeten Algorithmen
und deren effizienter Implementierung ab.
Einfluss der Algorithmen: Der erste Faktor der obigen Formel ist der Arbeitsaufwand,
dessen Einheit im Scientific Computing eine Gleitpunkt-Rechenoperation
- eine floating-point operation [flop] - ist. Die Rechenzeit hängt also
zunächst einmal von der Komplexität (dem Aufwand, den Kosten) der verwendeten
Algorithmen ab. Moderne Algorithmen mit niedriger Komplexität ermöglichen
signifikante Rechenzeitverkürzungen. Hier wurden in manchen Bereichen -
etwa durch die hoch-effizienten Multigrid-Verfahren zur numerischen Lösung
linearer Gleichungssysteme - ähnlich spektakuläre Fortschritte erzielt
wie in der Hardware-Entwicklung der letzten Jahrzehnte.
Einfluss der Hardware: Durch eine Steigerung der theoretischen Maximalleistung
eines Computersystems (gemessen in Gflop/s oder Tflop/s, also 109 bzw.
1012 flop/s) können ebenfalls die benötigten Rechenzeiten reduziert werden.
Da die meisten modernen Prozessoren - von PCs bis zu Großrechnern - sehr
ähnliche Leistungsdaten aufweisen, kann dies vor allem durch den gezielten
Einsatz von Parallelismus erreicht werden: Ein Rechner mit p Prozessoren
weist potentiell die p-fache Leistung eines entsprechenden Rechners mit
nur einem dieser Prozessoren auf. Die Rechenzeit kann daher im Prinzip
um den Faktor 1/p gesenkt werden.
Einfluss der Implementierung: Der Wirkungsgrad ist ein Hindernis, das sich
der sinnvollen Nutzung der theoretisch verfügbaren Maximalleistung mitunter
radikal in den Weg stellt. So kann die potentiell p-fache Leistung eines
Parallelrechners mit p Prozessoren nur dann real in einem akzeptablen Ausmaß
erreicht bzw. genutzt werden, wenn (1) alle Prozessoren möglichst weitgehend
ausgelastet sind, und zwar über die gesamte Zeit der rechnerischen Problemlösung
(also ein zufrieden stellender Lastausgleich herbeigeführt wird), (2) der
Zeitaufwand für Kommunikation und Synchronisation gering gehalten wird
sowie (3) die benötigte Zeit für Bereitstellung und Abtransport der Daten
zu und von den Prozessoren gering ist. Ein Algorithmus eignet sich nur
dann zum sinnvollen Einsatz auf Parallelrechnern, wenn er natürliche (inhärente)
Parallelität besitzt oder sich durch geeignete Umformungen parallelisieren
lässt. In jedem Fall sind die zwischen den Teilabschnitten des Algorithmus
bestehenden Abhängigkeiten entscheidend, ob und wie sinnvoll man eine Problemlösung
in parallel zu verarbeitende Teilschritte zerlegen kann oder nicht.
Aktuelle Computersysteme für das Hochleistungsrechnen
Cluster: Weltweit und nicht zuletzt auch bei den Serversystemen, die vom
Zentralen Informatikdienst (ZID) der TU Wien betrieben werden, geht seit
Jahren der Trend immer stärker weg von den klassischen eng gekoppelten
Parallelrechnern hin zu lose gekoppelten Systemen - Clustern, die aus einer
größeren Anzahl von PCs oder Spezial-Computern (den Knotenrechnern) zusammengesetzt
sind. Die Verbindung der Knotenrechner eines Clusters erfolgt durch ein
möglichst schnelles, dem aktuellen Stand der Technik entsprechendes Netzwerk.
Für den Benutzer tritt ein Cluster wie ein einzelner Parallelrechner mit
der entsprechenden Anzahl von Prozessoren in Erscheinung.
In der aktuellen Top500-Liste1 der leistungsstärksten Computer der Welt
werden bereits drei Viertel der dort angeführten Computersysteme dem Typus
des Clusters zugeordnet. Das Cluster-Computing hat auch bei den ZID- Servern
Einzug gehalten: Der neu installierte "Phoenix"- Server für numerisch intensives
Rechnen ist ein Cluster, der aus 65 Knotenrechnern mit je zwei Prozessoren
zusammengesetzt ist, die über ein schnelles InfiniBand- Netzwerk miteinander
kommunizieren.
Verteilte Systeme: Wenn die Koppelung der Knotenrechner einen noch loseren
Charakter annimmt als bei einem Cluster-System, dann spricht man meist
von einem verteilten System. Auch jedes verteilte System ist ein Zusammenschluss
unabhängiger (oft sehr heterogener) Computer, der sich für den Benutzer
als ein einzelnes System präsentiert. Die interagierenden Prozesse und
Prozessoren eines solchen Systems verfügen über keinen gemeinsamen Speicher
und kommunizieren daher über Nachrichten (message passing).
Grid-Systeme: Das Grundkonzept eines Computational Grids entspricht jenem
des power grids, also des Stromnetzes, wo der Stromverbraucher einfach
die angebotene Leistung nutzt und alles was jenseits der Steckdose passiert
für ihn verborgen bleibt: In einem Computational Grid stellt - im Idealfall
- der Konsument von Rechenleistung einfach eine Verbindung zum Rechennetz
her, so wie der Stromverbraucher eine Verbindung zum Stromversorgungsnetz
herstellt.
Grid-Computing ist eine spezielle Form des verteilten Rechnens, wo die
Rechenleistung vieler über das Internet verbundener (oft sehr unterschiedlicher)
Computer innerhalb eines virtuellen Netzwerks so zusammengefasst wird,
dass über den reinen Datenaustausch hinaus die zeitlich parallele Lösung
von rechenintensiven Problemen ermöglicht wird. Damit kann - mit deutlich
geringeren Kosten - die Rechenleistung heutiger Supercomputer übertroffen
werden. Die theoretisch verfügbare Maximalleistung von Grid-Systemen ist
in sehr einfacher Weise zu erhöhen: Es genügt das Hinzufügen von Rechnern
zum Netz oder ein hierarchisches Zusammenfassen von Grids zu übergeordneten
Grids. Praktisch gesehen benötigt man an Grid-Hardware nichts weiter als
mehrere Computer mit einer Netzwerkverbindung. Das Verteilen von Teilaufgaben
auf die Computer des so entstandenen Grid-Systems übernimmt eine spezielle
Grid-Software, die in der Regel auf einem zentralen Server läuft.
Nach der Struktur eines Grids kann man folgende Typen unterscheiden:
Cluster-Grids: Die einfachsten Grid-Systeme bestehen aus einem lokalen
Zusammenschluss von Computern, die durch ein Netzwerk miteinander verbunden
sind. Cluster Grids werden hauptsächlich zur Lösung rechenintensiver Aufgabenstellungen
innerhalb einer administrativen Domäne (z.B. eines Universitätsinstituts)
genutzt.
Campus-Grids und Global-Grids bestehen meist aus mehreren Grid-Clustern
in mehreren administrativen Domänen, die sich in verschiedenen Instituten,
Fakultäten oder Universitäten befinden können oder überhaupt weltweit verteilt
sind.
Nach dem Einsatzgebiet und der Aufgabenstellung sind folgende Typen unterscheidbar:
Distributed Supercomputing: Beim verteilten Hochleistungsrechnen werden
die Grid-Ressourcen dazu verwendet um rechenintensive Probleme zu lösen,
die auf einer einzelnen Maschine nicht lösbar sind. Die dabei zum Einsatz
gelangenden Rechner reichen von den Supercomputern eines EDV-Zentrums bis
zu einer größeren Menge von Arbeitsplatzrechnern, die im Moment nicht für
andere Aufgaben verwendet werden.
High-Troughput Computing: Dabei werden viele rechenintensive aber unabhängige
Aufgaben auf unbenutzten Ressourcen - wie etwa nicht oder nur wenig benutzten
Arbeitsplatzrechnern - bearbeitet. Große Grid-Anwendung dieser Art findet
man z. B. in kooperativen Projekten wie SETI@home oder distributed.net.
On-Demand Computing: On-Demand-Applikationen nutzen eine Grid-Infrastruktur
um kurzfristige Engpässe in der eigenen Rechenkapazität auszugleichen oder
um Ressourcen zu nutzen, die man selbst nicht kosteneffizient betreiben
kann.
Data-Intensive Computing: Bei Applikationen mit einem sehr großen Datenaufkommen
liegt der Schwerpunkt bei der Verteilung der Datenmenge über regional verteilte
Computersysteme, wie dies etwa beim EU-DataGrid2 der Fall ist.
Wie man dieser Aufstellung entnehmen kann, ist Grid- Computing als Basistechnologie
für numerische Simulationen sehr gut dafür geeignet, die im Bereich "Computational
Science and Engineering" ständig steigenden Ressourcenanforderungen mit
Hilfe verteilter Systemumgebungen zu erfüllen.
Die aktuelle Bedeutung des Grid-Computings kommt auch darin zum Ausdruck,
dass sich große EDV-Unternehmen wie etwa Sun oder Microsoft intensiv mit
dem Thema Grid-Computing befassen. So verkauft derzeit Sun in den USA Rechenkapazität
auf den unternehmenseigenen Grid-Computern und Microsoft wird noch im Laufe
des Jahres 2006 eine spezielle, für das Hochleistungsrechnen geeignete
Windows-Version herausbringen. Mit diesem neuen Betriebssystem wird es
möglich sein, Arbeitsplatz-PCs als Rechenknoten in Grid-Umgebungen zusammenzufassen.
Grid-Software
Wie man aus der Vielfalt der Formen und Anwendungen von Grid-Systemen leicht
schließen kann, ist es fast unmöglich die perfekte Grid-Software zu finden,
von der alle Anforderungen optimal abgedeckt werden. Als Ausgangspunkt
der Software-Auswahl ist es daher wichtig festzustellen, welche Aufgaben
von einem speziellen Grid zu übernehmen sind.
Um die brachliegenden Ressourcen an der TU Wien - wie etwa die Studenten-PCs
der Internet-Räume des ZID in den Nachtstunden und an Wochenenden - in
Form von Computational Grids nutzbar zu machen, kommen in erster Linie
On-Demand-Applikationen vom High-Through-put-Typ in Betracht. Für ein
derartiges Benutzungsprofil kommen folgende Softwarepakete in die engere
Wahl:
CONDOR3 ist ein primär für Workstation-Umgebungen vorgesehenes Lastverwaltungs-System,
das die optimale Ausnutzung der Knoten eines verteilten Systems anstrebt,
wobei der Versuch gemacht wird, den lokalen Benutzerbetrieb durch das Job-Scheduling
möglichst wenig zu stören. CONDOR wird seit mehr als 15 Jahren von einem
Team von 40 Angehörigen des Computer Science Departments der University
of Wisconsin / Madison ständig weiterentwickelt.
Das GLOBUS-Toolkit4, das von der Globus Alliance entwickelt wird, stellt
Services und Bibliotheken zum Bereitstellen, Überwachen und Verwalten von
Ressourcen sowie Software für das Sicherheits- und Datei-Management in
Grid-Systemen zur Verfügung. Mit diesen Tools können eigene Applikationen
"Grid-tauglich" gemacht werden.
Das GLOBUS-Toolkit hat sich im Laufe der vergangenen Jahre als der De-facto-Standard
zur Vernetzung lokaler Grid-Knotenrechner etabliert.
NETSOLVE und GRIDSOLVE: Den Systemen NETSOLVE und GRIDSOLVE5 - Software,
die von Jack Dongarra und seinen Mitarbeitern am Innovative Computing
Laboratory der University of Tennessee / Knoxville entwickelt wird - liegt
die Idee zugrunde, durch einfache, standardisierte Programmier-Interfaces
eine Verbindung zwischen Applikationen aus dem Scientific Computing und
einer Vielzahl verschiedener Rechen-Ressourcen herzustellen. Mit NETSOLVE
und GRIDSOLVE wird es in einfacher Weise möglich, wissenschaftliche Berechnungen
lokal am Arbeitsplatz zu starten, aber rechenintensive Teile auf besser
geeignete und aktuell verfügbare, leistungsstarke Computer-Systeme mit
Hilfe von NETSOLVE und GRIDSOLVE auslagern zu lassen.
UNICORE6 ist ein Software-Tool, das den sicheren und intuitiven Zugang
zu verteilten Grid-Ressourcen ermöglicht. Über ein grafisches Interface
werden dem UNICORE-System Jobs übergeben, die von diesem an ein Queueing-System
weitergeleitet werden, von dem die Ausführung der Jobs und die Rücksendung
der Ergebnisdaten an den Benutzer veranlasst wird.
Computer-Infrastruktur an der TU Wien
Das Scientific Computing wird durch die Bereitstellung einer hochschulweiten
Infrastruktur für rechenintensive Aufgabenstellungen gefördert. Den wissenschaft-
lichen Mitarbeitern und auch den Studenten der TU Wien steht - für das
Scientific Computing und auch für sonstige Arbeiten - Computer-Hardware
in verschiedener Form zur Verfügung.
Arbeitsplatzrechner: Am eigenen PC bestehen große Freiheiten hinsichtlich
dessen Nutzung. Will man dort aber rechenintensive Aufgabenstellungen lösen,
so steht man oft vor einem Dilemma: Räumt man der Lösung solcher Probleme
eine hohe Priorität ein, so steht der PC für die Dauer der Berechnung für
andere Arbeiten (Schreiben von Berichten, E-Mails etc.) nur in eingeschränktem
Maß zur Verfügung. Reduziert man aber die Priorität der rechenintensiven
Aufgabe soweit, dass für deren Lösung nur mehr die nicht anderweitig genutzte
Rechenkapazität verwendet wird, dann erhöht sich die Wartezeit bis zur
vollständigen Problemlösung unter Umständen dramatisch.
Um dieser Schwierigkeit zu entgehen, haben viele Institute und auch ganze
Fakultäten zusätzliche Rechner angeschafft oder Zugriffsrechte auf zentralen
Servern erworben, um rechenintensive Jobs auf spezieller Hardware bearbeiten
zu können ohne die Ressourcen der eigenen Arbeitsplatz-PCs zu überlasten.
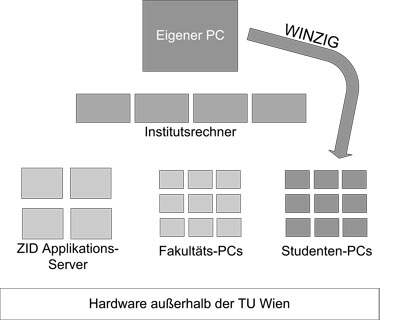
Zentrale Ressourcen: Über die Institutsebene hinausgehende Rechen-Ressourcen
stehen an der TU Wien in drei verschiedenen Formen zur Verfügung:
- Applikations-Server am ZID: Der Zentrale Informatikdienst (ZID) der TU Wien betreibt seit vielen Jahren parallele Hochleistungsrechner für spezielle Anwendungen wie auch zur freien Programmierung. Diese Computersysteme entsprechen (jedenfalls zum Zeitpunkt ihrer Anschaffung) dem aktuellen Stand der Technik, verfügen über eine sehr gute Hardware-Ausstattung (vor allem mit viel Memory) und sind für Anwendungen im Scientific Computing hoch optimiert. Aus diesem Grund verursachen sie meist relativ hohe Anschaffungskosten und besitzen auch nur eine verhältnismäßig kleine Zahl von Rechenknoten (Prozessoren).
- Fakultäts-PCs werden in eigenen Labors - wie etwa dem Informatik-Labor oder dem Architekten-Labor - von einzelnen Fakultäten zur Verfügung gestellt. Diese PCs sind auf spezielle Anwendungen zugeschnitten und für das Scientific Computing nicht so gut geeignet wie die Applikations-Server des ZID. Allerdings stellt die nicht direkt im Rahmen der widmungsgemäßen Verwendung genutzte Rechenleistung ein Potential für Anwendungen im Scientific Computing dar.
- Studenten-PCs werden vom ZID für die im Rahmen des Studiums täglich anfallenden Arbeiten der Studenten bereitgestellt. Diese PCs sind primär für Web-Recherchen, E-Mail-Aktivitäten sowie andere wenig rechenintensive Tätigkeiten gedacht. Die Studenten-PCs der TU Wien entsprechen (jedenfalls zum Zeitpunkt ihrer Anschaffung) dem aktuellen Stand der Technik und sind auch in relativ großer Zahl vorhanden. Wegen ihres speziellen Benutzungsprofils sind diese PCs im Hinblick auf Anwendungen im Scientific Computing nicht optimiert. Es gibt auch noch eine weitere Besonderheit: Die Studenten-PCs sind nur an Werktagen und nur unter Tags in Verwendung, viele von ihnen auch da nur zu Spitzenzeiten. Üblicherweise liegen diese Ressourcen in der Nacht und am Wochenende völlig brach. Die Nutzbarmachung dieses Potentials an Rechenleistung für das Scientific Computing an der TU Wien ist der Inhalt des vorliegenden Beitrags.
Eine Grid-Lösung für die TU Wien - WINZIG
Wie bereits beschrieben gibt es in den Internet-Räumen der TU Wien für
Studenten verfügbare PCs, die zu bestimmten Zeiten völlig unbenutzt sind.
Auf Grund der Heterogenität dieser PCs und deren Vernetzung bietet sich
bei der Erschließung dieser ungenutzten Rechenkapazitäten für das Scientific
Computing eine Grid-Lösung an. Dafür hat sich CONDOR im Rahmen einer Auswahl-
studie als gut geeignete Basis-Software herausgestellt. Es verfügt über
alle notwendigen Schnittstellen, um sowohl bereits verfügbare Software
verwendbar zu machen als auch MPI- und GLOBUS-Jobs in lokalen Grids wie
auch in nationalen oder internationalen Grid-Umgebungen ausführen zu können.
Die für die Entwicklung eines Campus-Gridsystems für die TU Wien eingesetzte
Version von CONDOR unterstützt Version 4 des GLOBUS-Toolkits. Damit werden
einer zukünftigen Nutzung in einem größerem Umfeld (z. B. durch Anbindung
an andere Grid-Systeme) keine Grenzen gesetzt.
Ausgangssituation: Die PCs der Internet-Räume sind alle ohne Festplatte
konfiguriert und werden von zwei Remote-Boot-Servern mit Linux-Images versorgt.
Als Betriebssystem steht Red Hat Linux mit KDE und diverser Anwendungs-Software
für den täglichen Bedarf zur Verfügung.
Umgestaltung zum Grid-System: In einem ersten Schritt in Richtung auf ein
Campus-Grid-System an der TU Wien wurde die vorhandene System-Software
für die vom ZID betriebenen Internet-Räume so modifiziert, dass zu den
betriebsfreien Zeiten in der Nacht und an Wochenenden ein anderes Image
gebootet wird und die Rechner dann als Grid-Knoten zur Verfügung stehen.
Mit Hilfe eines eigenen dritten Boot-Servers wurde die Möglichkeit geschaffen,
zu bestimmten Zeiten ein anderes Boot-Image auf die Studenten-PCs zu laden.
Dieses Image ist für das Scientific Computing spezialisiert und wurde mit
dafür geeigneter Software ausgestattet (Intel C Compiler und Fortran Compiler,
Intel MKL).
Mit CONDOR werden die Studenten-PCs zu einem Campus-Grid zusammengefasst,
dessen Knotenrechner von einem eigenen zentralen Grid-Master mit Jobs versorgt
werden.
Benutzung: Der Einstieg in WINZIG erfolgt über den Grid-Master, wo die
Jobs kompiliert und in eine Queue gestellt werden. Diese Jobs werden dann
von CONDOR auf einem oder mehreren passenden Rechnern des Campus-Grids
zur Ausführung gebracht. Nach Beendigung des Jobs stehen die dafür verwendeten
PCs sofort wieder für weitere Berechnungen desselben Benutzers oder für
andere Benutzer zur Verfügung. Für Jobs, deren Ausführung in einer Nacht
oder an einem Wochenende zu keinem Abschluss gelangt, gibt es unter CONDOR
die Möglichkeit des Unterbrechens und der weiteren Ausführung zu einem
späteren Zeitpunkt.
Anwender des Grid-Systems WINZIG
Es gibt bereits einige Gruppen an der TU Wien, die Scientific Grid-Computing
mit Hilfe von WINZIG auf der Infrastruktur der Studenten-PCs betreiben:
Institut für Photonik: Die an diesem Institut entwickelte Software zur
Simulation der Wirkungen ultrakurzer Laserimpulse konnte unter WINZIG kompiliert
werden und läuft ohne weitere Adaptierung auf dem Campus-Grid, das von
den Studenten-PCs der TU Wien gebildet wird. Die einzige Einschränkung
ist durch die relativ kleinen Speicher der Knotenrechner gegeben, die das
Bearbeiten speicherintensiver Problemstellungen auf den Studenten-PCs unmöglich
machen.
Da das Scheduling der an diesem Institut installierten Computer-Systeme - so wie beim WINZIG-System - ebenfalls mit Hilfe von CONDOR erfolgt, ist ein Zusammenschluss der Instituts-Hardware mit dem Campus-Grid in einfacher Weise realisierbar und wurde auch als zukünftiges Projekt ins Auge gefasst.
Da das Scheduling der an diesem Institut installierten Computer-Systeme - so wie beim WINZIG-System - ebenfalls mit Hilfe von CONDOR erfolgt, ist ein Zusammenschluss der Instituts-Hardware mit dem Campus-Grid in einfacher Weise realisierbar und wurde auch als zukünftiges Projekt ins Auge gefasst.
Institut für Mikroelektronik: Das hier entwickelte Software-Paket MINIMOS-NT
zur Simulation von Halbleiterbauelementen läuft auf WINZIG. Da aber für
die institutseigene Hardware ein anderer Scheduler verwendet wird, ist
deren Kopplung mit dem Campus-Grid zwar möglich, würde aber zusätzliche
Software erfordern.
Am Institut für Mikroelektronik wird bereits eine Grid-Lösung - ein Cluster-Grid - erfolgreich eingesetzt, bei der Laborrechner in der Nacht als Grid-Knoten für Problemstellungen des Scientific Computing eingesetzt werden.
Am Institut für Mikroelektronik wird bereits eine Grid-Lösung - ein Cluster-Grid - erfolgreich eingesetzt, bei der Laborrechner in der Nacht als Grid-Knoten für Problemstellungen des Scientific Computing eingesetzt werden.
Institut für Materialchemie: Die an diesem Institut entwickelte Software
WIEN2k, ein auf der Dichte-Funktional-Theorie beruhendes Software-Paket
zur rechnerischen Ermittlung der Materialeigenschaften von Festkörpern,
wurde erfolgreich auf WINZIG getestet. Derzeit laufen Bemühungen, den Scheduler
von WIEN2k so zu erweitern, dass er auch mit CONDOR-Umgebungen zurecht
kommt. Sobald dies der Fall sein wird, können WIEN2k-Berechnungen problemlos
am Campus-Grid der TU Wien durchgeführt werden.
Zusammenfassung und Ausblick
Das Grid-System WINZIG erschließt dem Scientific Computing an der TU Wien
neue und sehr beachtliche Ressourcen. Die theoretische Maximalleistung
des gesamten Systems entspricht der Leistung eines Supercomputers. Sie
liegt derzeit bei beachtlichen 2,6 Tflop/s (also 2600 Milliarden Gleitpunkt-Rechenoperationen
pro Sekunde) bei Rechnung in einfacher Genauigkeit und Nutzung der SIMD-Erweiterungen
(SSE, SSE2 etc.) der vorhandenen Prozessoren. Mit den SIMD-(Single Instruction
Multiple Data)-Befehlen können einzelne Operationen auf ganze Blöcke von
zwei oder vier Gleitpunkt- Daten angewendet werden und ermöglichen damit
eine Verdoppelung oder Vervierfachung der potentiellen Maximalleistung.
Ohne Verwendung dieser SIMD-Befehle beträgt die theoretische Maximalleistung
des Campus- Grids immerhin noch 668 Gflop/s.
Bisher werden die durch das Grid-System WINZIG nutzbar gemachten Ressourcen
nur wenig in Anspruch genommen, da es derzeit nur einen geringen Bekanntheitsgrad
besitzt. Es gibt zwar einige Einschränkungen (der Hauptspeicher der PCs
umfasst meist nur 512 MB RAM und die Vernetzung ist mit einer Übertragungsrate
von 100 Mbit/s weit von den derzeit schnellsten Verbindungen entfernt),
aber für bestimmte Aufgaben - wie etwa Parameterstudien, wo ein und dasselbe
Programm mit einer Vielzahl verschiedener Daten gestartet wird - kann das
Campus-Grid der TU Wien mit seinen meist um die 150 verfügbaren Rechnern
sehr vorteilhaft eingesetzt werden.
In Zukunft könnten auf der Basis von WINZIG auch Instituts-Grids (Cluster-Grids)
in größerer Zahl errichtet werden. Damit würden Ressourcen, die sich durch
die in kürzeren oder längeren Zeitabschnitten brachliegende Leistung
von Institutsrechnern ergibt, dem Scientific Computing zur Verfügung stehen.
Literatur
A. Abbas: Grid Computing: A Practical Guide to Technology and Applications,
Charles River Media, 2003.
F. Berman, G. Fox, A. Hey (Eds.): Grid Computing: Making the Global Infrastructure
a Reality, Wiley, 2003.
B. Di Martino, J. Dongarra, A. Hoisie, L. Tianruo Yang, H. Zima (Eds.):
Engineering The Grid: Status and Perspective, American Scientific Publishers,
2006.
C. Fellenstein, J. Joseph: Grid Computing, IBM Press, 2004.
I. Foster, C. Kesselman (Eds.): The Grid: Blueprint for a New Computing
Infrastructure, Elsevier, 2. Auflage, 2004.
D. Janakiram (Ed.): Grid Computing: A Research Monograph, Tata McGraw-Hill,
2005.
P. Kolmann: University Campus Grid Computing, Diplomarbeit, TU Wien, 2005.
M. Li, M. Baker: The Grid: Core Technologies, Wiley, 2005.
D. Minoli: A Networking Approach to Grid Computing, Wiley, 2004.
P. Plaszczak, R. Wellner: Grid Computing: The Savvy Manager's Guide, Morgan
Kaufmann, 2005.
|
Falls dieser Artikel Ihr Interesse geweckt hat und Sie über eine Applikation verfügen, die unter dem Grid-System WINZIG laufen könnte, dann melden Sie sich bitte. Wir können dann gemeinsam besprechen, wie in Ihrem konkreten Fall die bestmögliche Nutzung des Campus-Grids der TU Wien aussieht. Kontakt: Philipp Kolmann, @zid.tuwien.ac.at, Klappe 42011. |
1 www.top500.org
2 http://eu-datagrid.web.cern.ch/eu-datagrid/
3 http://www.cs.wisc.edu/condor/
4 http://www.globus.org/toolkit/
5 http://icl.cs.utk.edu/netsolve/
6 http://www.unicore.org/