Phoenix Software und Benchmarks
In den Sommermonaten wurde der neue Sun HPC-Cluster (phoenix.zserv) in
Betrieb genommen. Während die Hardware bereits in früheren Artikeln vorgestellt
worden sind, steht die Software im Mittelpunkt dieses Artikels.
Betriebssystem
Auf allen Knoten ist derzeit Fedora Core 3 für AMD 64 mit den aktuellen
Updates installiert (Kernel 2.6.9). Ein Umstieg auf Fedora Core 4 ist derzeit
nicht möglich, da die Mellanox Infiniband Software derzeit nur für Fedora
Core 3 freigegeben ist. Prinzipiell können unter diesem Betriebssystem
auch 32 Bit Applikationen ausgeführt werden; in der Praxis treten aber
häufig Probleme auf, da nicht immer alle benötigten Libraries auch als
32 Bit Version vorliegen.
Compiler
Neben der GNU Compiler Collection (gcc) in der Version 3.4.4 stehen die
folgenden C, C++ und Fortran Compiler zur Verfügung:
- PathScale EKOPath Compiler Suite (Version 2.2.1)
-
Intel Compilers for Linux
(Version 9.0) - PGI Cluster Development Kit (CDK) (Version 6.0.5)
Derzeit stehen zwei Lizenzen der PathScale Compiler zur Verfügung. Von
den PGI Compilern stehen fünf Lizenzen bis Ende Jänner 2006 zur Verfügung;
eine Verlängerung ist derzeit nicht geplant. Für die Intel Compiler besteht
kein Wartungsvertrag; sie stehen somit ohne Limitierung zur Verfügung,
wurden aber bisher kaum getestet.
InfiniBand Software
Die InfiniBand Hardware stammt von Mellanox; der mitgelieferte Software
Stack IBGold ist sehr umfangreich und umfasst die in Abbildung 1 angeführten
Software Layer.
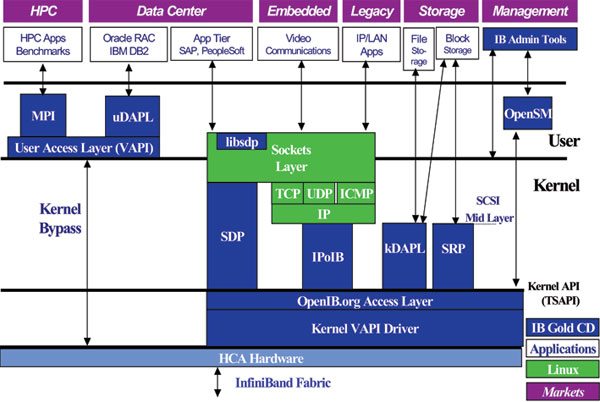
Abb. 1: IBGD Stack
Der für den Benutzer interessante Teil ist der HPC/MPI Bereich. Verwendet
wird mvapich (Version 0.9.5), eine MPI-Implementierung der Ohio State
University. Wie in der Abbildung ersichtlich, nützt mvapich einen user
access layer (VAPI) um direkt und unter Umgehung der Kernel Driver auf
die HCA-Hardware zuzugreifen. Dadurch sollen möglichst geringe Latenzzeiten
erreicht werden.
Die Administration erfolgt über OpenSM.
Neben dem InfiniBand Netzwerk sind die einzelnen Knoten auch noch mit Gigbit
Ethernet miteinander verbunden. Mittels IPoIB (Internet Protocol over Infini
Band) könnte aber auch NFS-Verkehr über das Infini Band Netzwerk realisiert
werden.
Damit eine MPI Applikation Infiniband nutzen kann, müssen bei der Erstellung
des Codes entsprechende Optionen für das Kompilieren und Linken angegeben
werden. Je nach verwendetem Compiler sind unter- schiedliche Optionen anzuwenden.
Die IBGD-Software unterstützt derzeit die GNU, Pathscale und PGI Compiler.
Mit und für jeden dieser Compiler wird die mvapich Software extra generiert
und dem Anwender über entsprechende Scripts zur Verfügung gestellt (z. B.
mpif90 zum Kompilieren und Linken von MPI Fortran Programmen; die Scripts
sollten aber mit absoluten Namen aufgerufen werden, Details dazu finden
sich in der Dokumentation zum Cluster).
Optimierung
Alle Compiler stellen eine Vielzahl von Optimierungsmöglichkeiten zur Verfügung.
Um dem Anwender die Auswahl zu erleichtern, werden diese in Gruppen zu
Optimierungstufen zusammengefasst; je höher die Optimierungsstufe, desto
mehr Optimierungsoperationen führt der Compiler durch. In der Theorie sollte
man mit einer höheren Optimierungsstufe auch eine bessere Laufzeit erzielen.
In der Praxis zeigt sich meist ein anderes Bild.
Eine höhere Optimierungsstufe ist keinesfalls ein Garant für eine bessere
Laufzeit: in vielen Fällen kann aggressives Optimieren zu schlechteren
Laufzeiten, größeren numerischen Fehlern oder im Extremfall zu Programmabbrüchen
führen. Da in einem Compiler sehr viele Stufen (beim gcc z. B. über 100)
jeweils Transformationen am Code vornehmen, können verbesserte Optimierungen
in einer bestimmten Stufe zu einem Output führen, der für die nachfolgenden
Stufen keine oder nur mehr eingeschränkte Optimierungen zulässt.
Grundsätzlich sollte während der Programmentwicklung auf (aggressive) Optimierung
verzichtet werden; erst sobald ein lauffähiger Code vorhanden ist, sollte
die Optimierungsstufe gesteigert werden. Nach jedem Opti- mierungsschritt
sollten die Laufzeiten und die Resultate verglichen werden.
Bibliotheken
Für numerisch intensive Applikationen im Bereich der linearen Algebra gibt
es seit Jahren einen defacto Standard: LAPACK und BLAS. LAPACK bietet unter
anderem Routinen zur Lösung linearer Gleichungssysteme und von Eigenwertproblemen.
In der BLAS werden einfachere Routinen wie Matrizenmultiplikation zur Verfügung
gestellt. Für die Generierung von effizientem Code ist die Verwendung von
optimierten Versionen dieser Bibliotheken notwendig:
ACML:
die AMD Core Math Library enthält neben LAPACK und BLAS auch noch FFT-Routinen und ist von AMD speziell auf AMD64 und Opteron Prozessoren optimiert worden.
die AMD Core Math Library enthält neben LAPACK und BLAS auch noch FFT-Routinen und ist von AMD speziell auf AMD64 und Opteron Prozessoren optimiert worden.
ATLAS:
steht für Automatically Tuned Linear Algebra Subroutines und ist der Versuch, durch Testen und Bewerten einer großen Anzahl möglicher Implementierungen automatisch eine für die jeweilige Architektur optimal angepasste Version zu erstellen. ATLAS enthält BLAS und wenige Teile von LAPACK.
steht für Automatically Tuned Linear Algebra Subroutines und ist der Versuch, durch Testen und Bewerten einer großen Anzahl möglicher Implementierungen automatisch eine für die jeweilige Architektur optimal angepasste Version zu erstellen. ATLAS enthält BLAS und wenige Teile von LAPACK.
GotoBLAS:
wärend sich viele Implementierungen effizienter Routinen zur Matrizenmultiplikation bei der Optimierung auf die möglichst effiziente Ausnutzung der Speicherhierarchie (im Wesentlichen der Level 1 und Level 2 Caches) konzentrieren, steht bei der GotoBLAS die Minimierung der Transition Lookaside Buffer (TLB) Misses im Zentrum (der TLB ist ein schneller Zwischenspeicher für oft benötigte Zuordnungen zwischen virtuellen und physikalischen Speicheradressen; wird eine Zuordnung nicht im TLB gefunden (TLB miss), muss aufwendig in entsprechenden Tabellen gesucht werden).
Die GotoBLAS ist für die meisten aktuellen Architekturen erhältlich und bietet in den meisten Fällen die effizienteste BLAS-Implementierung. Der Name rührt vom Hauptautor, Kazushige Goto, her.
wärend sich viele Implementierungen effizienter Routinen zur Matrizenmultiplikation bei der Optimierung auf die möglichst effiziente Ausnutzung der Speicherhierarchie (im Wesentlichen der Level 1 und Level 2 Caches) konzentrieren, steht bei der GotoBLAS die Minimierung der Transition Lookaside Buffer (TLB) Misses im Zentrum (der TLB ist ein schneller Zwischenspeicher für oft benötigte Zuordnungen zwischen virtuellen und physikalischen Speicheradressen; wird eine Zuordnung nicht im TLB gefunden (TLB miss), muss aufwendig in entsprechenden Tabellen gesucht werden).
Die GotoBLAS ist für die meisten aktuellen Architekturen erhältlich und bietet in den meisten Fällen die effizienteste BLAS-Implementierung. Der Name rührt vom Hauptautor, Kazushige Goto, her.
MKL:
in der Intel Math Kernel Library sind neben BLAS und LAPACK auch iterative und direkte Methoden zur Lösung schwach besetzter linearer Gleichungssysteme, FFT-Routinen sowie zusätzliche mathematische und statistische Routinen vorhanden. Verfügbar ist die MKL für alle gängigen Intel Prozessoren (Itanium-2, Pentium 4, Xeon) aber auch AMD Athlon64 und Opteron Prozessoren.
in der Intel Math Kernel Library sind neben BLAS und LAPACK auch iterative und direkte Methoden zur Lösung schwach besetzter linearer Gleichungssysteme, FFT-Routinen sowie zusätzliche mathematische und statistische Routinen vorhanden. Verfügbar ist die MKL für alle gängigen Intel Prozessoren (Itanium-2, Pentium 4, Xeon) aber auch AMD Athlon64 und Opteron Prozessoren.
Alle angeführten Bibliotheken sind am Sun Cluster verfügbar.
Performance-Tools
Unter Linux stehen eine Reihe von Tools zur Verfügung, die helfen, die
Effizienz eines Codes zu beurteilen.
time/times:
Mit den Kommando time bzw. dem System Call times kann die Laufzeit vom Programmen bzw. Programmteilen gemessen werden.
Mit den Kommando time bzw. dem System Call times kann die Laufzeit vom Programmen bzw. Programmteilen gemessen werden.
valgrind:
Mit diesem Emulator kann das Verhalten eines Programmes sehr genau analysiert werden; es bietet z. B. einen Cache Simulator, mit dem die Ausnutzung der Cache Speicher ermittelt werden kann. Da der dafür notwendige Aufwand sehr hoch ist, muss mit wesentlich höheren Laufzeiten (mindestens Faktor 20!) gerechnet werden.
Weiters gibt es einen so genannten "Memory Checker", der die Allokierung und Freigabe von Speicherbereichen analysiert und in der Praxis sehr hilfreich sein kann.
Mit diesem Emulator kann das Verhalten eines Programmes sehr genau analysiert werden; es bietet z. B. einen Cache Simulator, mit dem die Ausnutzung der Cache Speicher ermittelt werden kann. Da der dafür notwendige Aufwand sehr hoch ist, muss mit wesentlich höheren Laufzeiten (mindestens Faktor 20!) gerechnet werden.
Weiters gibt es einen so genannten "Memory Checker", der die Allokierung und Freigabe von Speicherbereichen analysiert und in der Praxis sehr hilfreich sein kann.
Oprofile:
Bei oprofile wird nicht nur ein einzelner Prozess, sondern das gesamte System beobachtet. Daher ist es besonders prädestiniert zum Auffinden von performance bottlenecks im System. Entspechend der eingestellten Sampling Rate und der gewünschten Hardware Counter wird eine Vielzahl von Daten akkumuliert, die dann mit opreport selektiert ausgegeben werden. Für das Starten/Stoppen des Profilings werden Root-Rechte benötigt; am Cluster können interessierte Benutzer dies über sudo durchführen.
Bei oprofile wird nicht nur ein einzelner Prozess, sondern das gesamte System beobachtet. Daher ist es besonders prädestiniert zum Auffinden von performance bottlenecks im System. Entspechend der eingestellten Sampling Rate und der gewünschten Hardware Counter wird eine Vielzahl von Daten akkumuliert, die dann mit opreport selektiert ausgegeben werden. Für das Starten/Stoppen des Profilings werden Root-Rechte benötigt; am Cluster können interessierte Benutzer dies über sudo durchführen.
PAPI:
Das Performance API (PAPI) spezifiziert ein standardisiertes Interface für den Zugriff auf Hardware Counter und bietet eine Reihe entsprechender Tools. PAPI benötigt einen Kernel Patch, der derzeit mit der bestehenden Kernel-Konfiguration nicht kombatibel ist.
Das Performance API (PAPI) spezifiziert ein standardisiertes Interface für den Zugriff auf Hardware Counter und bietet eine Reihe entsprechender Tools. PAPI benötigt einen Kernel Patch, der derzeit mit der bestehenden Kernel-Konfiguration nicht kombatibel ist.
Benchmarks
Mit der Einführung der EM64T Technologie bietet auch Intel seit einiger
Zeit 64-Bit Prozessoren im x86-Umfeld an. Intel EM64T Technologie ist fast
vollständig mit der AMD64 Spezifikation kompatibel, sodass zum Beispiel
Intel Compiler oder die MKL auch auf Opteron Systemen eingesetzt werden
können. Es gibt teilweise sehr heftig geführte "Glaubenskriege", welcher
Hersteller das bessere Konzept habe und die leistungsfähigeren Prozessoren
herstellen würde.
Durch die Integration des Memory-Controllers auf dem Prozessor Chip haben
AMD Opteron-basierte Systeme eine deutlich höhere Speicherbandbreite zur
Verfügung als Intels Xeon Prozessoren, wo sich die beiden Prozessoren einen
gemeinsamen Speicherbus teilen müssen. Dafür ist der Xeon Prozessor deutlich
höher getaktet, wodurch Applikationen, die die SSE-3 Einheit effizient
ausnutzen können, deutlich schneller laufen als auf Opteron Prozessoren.
Von der Standard Performance Evaluation Corporation (SPEC) wird eine Reihe
von Benchmarks herausgegeben; für den HPC-Bereich ist der SPECfp2000-Wert
von Interesse, eine Sammlung von insgesamt 14 Benchmark Programmen. In
den Tabellen werden ein Opteron System (Sun V20z mit zwei Opteron 2.4
GHz) und ein Xeon System (IBM x336 mit zwei Xeon 3.6 GHz und 1 MB L2 Cache)
verglichen. Beim SPECfp2000-Wert liegt das Opteron System deutlich vorne
(1747 zu 1641), bei einzelnen Benchmarks ist aber dennoch das Intel System
schneller (zum Beispiel liegt beim equake Benchmark das Xeon System mit
67,1 Sekunden zu 95,3 Sekunden deutlich voran).
Ein oft nicht erwähnter Faktor bei derartigen Vergleichen ist die verwendete
Software, speziell die verwendeten Compiler und Bibliotheken. Die angeführten
Resul- tate für die V20z wurden mit den PathScale Compilern erreicht, die
Werte bei Verwendung der PGI Compiler sind deutlich niedriger (1550).
Da beim SPECfp2000-Benchmark nur ein Prozessor benutzt wird, kann man damit
die maximal erreichbare Spitzenleistung eines Systems illustrieren, aber
kaum Aussagen über den Gesamtdurchsatz eines Systems treffen. Dazu dient
der SPECfp2000_rate, bei dem die gleichen Benchmark-Programme verwendet
werden, aller- dings werden die Programme zeitgleich von allem Prozessoren
ausgeführt. Hier kann das Opteron System dank seiner überlegenen Speicherbandbreite
eine Wert von 38.7 verbuchen, während das Xeon basierte System nur einen
Wert von 28.6 erreicht.
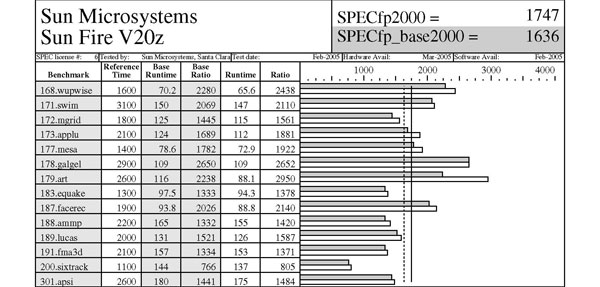
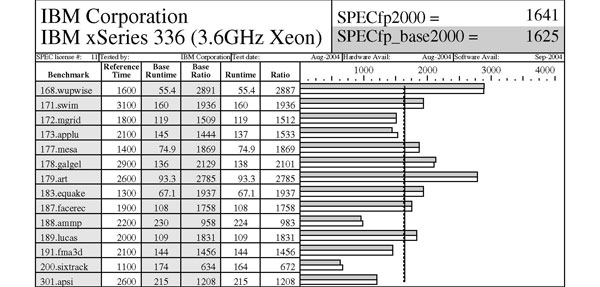
Tabelle SPECfp2000 Benchmark
Linpack-Benchmark
Die Top500 Liste ist eine Reihung der 500 leistungsfähigsten Rechnersysteme
weltweit. Als Bewertungskriterium wird der Linpack-Benchmark, das direkte
Lösen eines linearen Gleichungssystems, herangezogen. Mit dem Sun Cluster
wurden beim Linpack Benchmark 530 Gflop/s bei Verwendung von 130 CPUs erreicht.
Um in die Top500 aufgenommen zu werden, ist mittlerweile eine Leistung
von deutlich mehr als ein Tflop/s notwendig. In der Liste vom November
1996 hätten 530 Gflop/s unangefochten für den ersten Platz gereicht, und
im November 2000 immerhin noch für Platz 29.
Links
ZID Sun Cluster: http://www.zserv.tuwien.ac.at/phoenix/
valgrind: http://valgrind.org/
oprofile: http://sourceforge.net/projects/oprofile/
PathScale: http://www.pathscale.com/
PGI: http://www.pgroup.com/
GotoBLAS: http://www.tacc.utexas.edu/resources/software/
MKL: http://www.intel.com/cd/software/products/asmo-na/eng/ perflib/index.htm
ATLAS: http://math-atlas.sourceforge.net/
PAPI: http://icl.cs.utk.edu/papi/
SPEC: http://www.spec.org/
TOP500: http://www.top500.org/
valgrind: http://valgrind.org/
oprofile: http://sourceforge.net/projects/oprofile/
PathScale: http://www.pathscale.com/
PGI: http://www.pgroup.com/
GotoBLAS: http://www.tacc.utexas.edu/resources/software/
MKL: http://www.intel.com/cd/software/products/asmo-na/eng/ perflib/index.htm
ATLAS: http://math-atlas.sourceforge.net/
PAPI: http://icl.cs.utk.edu/papi/
SPEC: http://www.spec.org/
TOP500: http://www.top500.org/