TU Wien | ZID | ZIDline 8 | Ausfallsicherheit und Redundanz im TUNET
1. Einleitung
2. Grundbegriffe
3. Der Weg zwischen zwei Rechnern an der TU Wien
4. Der Weg ins Internet
5. Maßnahmen bei Servern
6. Telefonie
7. Management
8. Literatur
Das Datennetz der Technischen Universität Wien versorgt derzeit ca. 9000 Endsysteme. Im Tagesschnitt werden von den Mailbastionsrechnern ca. 22000 Mails weitergeleitet, ca. 45000 Mails werden pro Tag auf den zentralen Mailservern auf Viren überprüft. Allein schon aus diesen wenigen Zahlen ist die Bedeutung des Datennetzes für den Betrieb unserer Universität ersichtlich. Die Datenkommunikation und der Zugriff auf Ressourcen im Internet bzw. das Anbieten von Ressourcen im Internet ist aus dem heutigen Leben nicht mehr wegzudenken.
Seit einigen Jahren ist daher die Verbesserung der Betriebssicherheit ein wesentlicher Schwerpunkt bei den Erweiterungen im TUNET inklusive der zum TUNET dazugehörigen Server. Anzumerken ist, dass schon alleine die Aufrechterhaltung der gleichen subjektiven Betriebssicherheit große Anstrengungen und Investitionen erfordert.
Alle hier diskutierten Maßnahmen beziehen sich nur auf das IP-Protokoll. Bei eventuell verwendeten anderen Protokollen können ein Teil der Maßnahmen auch greifen, von der Struktur des TUNET wird jedoch die Ausfallsicherheit nur für IP (v4) unterstützt.
Wenn man bedenkt, dass im günstigen Fall und vereinfacht zur Kommunikation von zwei Rechnern in zwei verschiedenen Standorten der TU Wien 4 Glasfaser- strecken, 2 Kupferstrecken, 12 Patchkabel, 2 Switches, 3 Backbone Switche/Router, ein Nameserver (der in einem anderen Gebäude steht und damit wieder 1 Kupfer- strecke, 2 Glasfaserstrecken und 6 Patchkabel sowie 2 Switche benötigt) sowie insgesamt 8 230V Stromanschlüsse erforderlich sind, so kommt man unter Vernachlässigung von Komponenten wie Klima auf insgesamt 43 Komponenten.
Wenn nun vereinfacht jede Komponente eine Ausfallwahrscheinlichkeit von 0,1% hätte, so ergibt dies für den gesamten Kommunikationsweg eine Ausfallwahrscheinlichkeit von 4,2%, dies wäre im Schnitt an einem Tag im Monat eine Störung (wie lange dann immer die Fehlerbehebung dauert). Zum Glück sind die Ausfallwahrscheinlichkeiten deutlich geringer, aber bei einem derart großen und komplexen System wie dem TUNET fragt man sich trotzdem manchmal, wieso alles funktioniert (die meiste Zeit sind aber eh irgendwelche Störungen zu beheben und wir kommen auf diese Gedanken gar nicht).
Wichtige Größen zur Beurteilung der Betriebssicherheit sind auch MTBF (Mean Time Between Failure) und MTTR (Mean Time to Repair).
| zufällige, physikalische Fehler |
| Verschleißfehler, z.B. durch alterung elektrischer Bauteile |
| Störungsbedingte Fehler aufgrund äußerer physikalischer Einflüsse, z.B. Stromausfall, Wassereinbruch |
| Bedienungsfehler |
| Wartungsfehler: fehlerhafte Systemeingriffe während Wartungsintervall |
| Sabotage, Vandalismus |
| Umbaumaßnahmen |
Neben den eigentlichen Betriebsfehlern gibt es noch die geplanten Unterbrechungen, z.B. infolge von Erweiterungen und Umbauten, Überprüfungen (z.B. der Stromversorgung, Test der Redundanzmaßnahmen, Reproduzieren von Fehlern).
| Typ | Verhalten des Systems |
| (go) | System arbeitet sicher und korrekt |
| (fail-operational) | System fehlertolerant ohne Leistungsverminderung |
| (fail-soft) | Systembetrieb sicher, aber Leistung vermindert |
| (fail-safe) | Nur Systemsicherheit gewährleistet |
| (fail-unsafe) | unvorhersehbares Systemverhalten |
Bei der Korrektur von Fehlern unterscheidet man die zwei Prinzipien der Vorwärts- und der Rückwärtsfehlerkorrektur. Bei der Vorwärtsfehlerkorrektur versucht das System, so weiterzumachen als ob kein Fehler aufgetreten wäre, indem es z. B. im Moment des Auftretens eines Fehlers sofort mit korrekt funktionierenden Ersatz- systemen weiterarbeitet. Fehler bleiben bei der Vorwärtsfehlerkorrektur normalerweise unsichtbar für Anwender. Bei der Rückwärtsfehlerkorrektur versucht das System bei Auftreten eines Fehlers in einen Zustand vor diesem Auftreten zurückzukehren, z. B. in den Zustand direkt vor einer fehlerhaften Berechnung, um diese Berechnung erneut auszuführen. Genauso ist aber auch ein Zustandswechsel in einen Notbetrieb oder z. B. ein Reboot des Systems möglich. Kann eine fehlerhafte Berechnung erfolgreich wiederholt werden, bleibt auch bei der Rück- wärtsfehlerkorrektur der Fehler für den Anwender unsichtbar. Oft ist aber nur ein Weiterbetrieb mit Leistungseinbußen oder eingeschränkter Funktionalität möglich und der Fehler somit sichtbar.
Man unterscheidet dabei verschiedene Stufen der Redundanz.
| Aktive-Redundanz (funktionsbeteiligte, heiße Redundanz) | Mehrere Komponenten eines Systems führen dieselbe Funktion simultan aus. Fällt eine Komponente aus, wird dieser Fehler durch die verbleibenden Komponenten direkt kompensiert und führt daher nicht unmittelbar zu einer von außen erkennbaren Reaktion. Normalerweise erfolgt dann zwischen allen aktiven Systemen eine Lastaufteilung. |
| Standby-Redundanz (passive Redundanz) | Zusätzliche Mittel sind eingeschaltet/bereitgestellt, werden aber erst bei Ausfall/Störung an der Ausführung der vorgesehenen Aufgabe beteiligt. |
| Kalte Redundanz | Zusätzliche Mittel werden erst bei Ausfall/Störung eingeschaltet/bereitgestellt. |
Im Bereich der Vernetzung können die getroffenen Maßnahmen zusätzlich wie folgt klassifiziert werden:
| Geräteredundanz | Für eine Funktion gibt es mindestens zwei voneinander unabhängige (wie genau das erreichbar ist, hängt von der jeweiligen Funktion ab) Systeme, die diese Funktion erbringen. |
| Wegeredundanz | Für eine Verbindung zwischen zwei Systemen gibt es mindestens zwei voneinander unabhängige Wege. |
| Raumredundanz | Die Funktion kann in zwei verschiedenen Räumen eines Gebäudes erbracht werden. |
| Gebäuderedundanz | Die Funktion kann in zwei verschiedenen Gebäuden der TU Wien erbracht werden. |
| von | nach | via | Maßnahme |
| PC/Ethernetkarte | Etagen Switch Port | TP-Kabel | Keine Ausfallsicherheit durch TUNET möglich. Siehe 3.1 |
| Etagen Switch | Gebäude Switch | Glasstrecke | Pro Gebäude 2 Backbone Switche. Je ein Weg zu jedem Gebäude Switch. Siehe 3.2 |
| Gebäude Switch | Gebäude Router | Intern oder Glasstrecke | Pro Gebäude 2 Backbone Router. Siehe 3.3 |
| Gebäude Router/Switch | Core-Router | Glasstrecke | 2 Core Router auf der TU Wien. Je ein Weg zu jedem Gebäude-Switch. Siehe 3.3 |
| Core Router | Gebäude Router/Switch | Glasstrecke | Pro Gebäude 2 Backbone Router + Switche. Siehe 3.3 |
| Gebäude Router/Switch | Etagen Switch | Glasstrecke | 2 Wege zum Etagen Switch. Siehe 3.2 |
| Etagen Switch | POP-Server | TP-Kabel | Keine Ausfallsicherheit durch TUNET möglich. Siehe 3.1. Server siehe 5. |
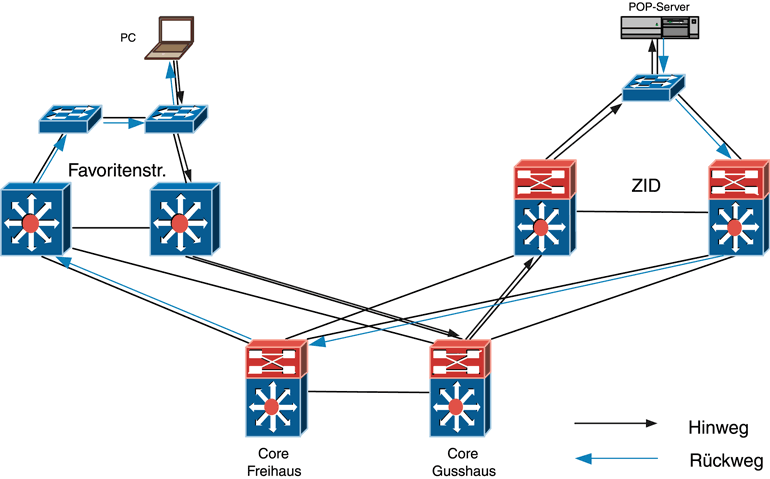
Der Ablauf ist auch in folgender Grafik dargestellt:
Bei den Etagenswitchen handelt es sich normalerweise um nichtmodulare Geräte mit 24, 48 oder 80 Ports, die nur ein Netzteil haben. Es ist daher eine Stromversorgung mit zwei unabhängigen Stromkreisen nicht möglich. Es wird jedoch (zumindest bei Neuerrichtungen) sichergestellt, dass die Stromversorgung durch eine eigene Absicherung mit FI/LS (kombinierter FI Schutzschalter mit Leistungsschalter) erfolgt und nicht mit Licht, Klima, Staubsaugersteckdosen etc. zusammenhängt. Bei größeren Etagenverteilern wird auch eine eigene USV eingesetzt. Normalerweise ist die Aufrechterhaltung des Betriebes bei Ausfall des Stromes im Etagenverteiler nicht so wichtig, da es sich meistens um Stromausfälle handelt, die auch die Rechner am Institut betreffen (können auf Grund der maximalen TP-Kabellänge von 90 Metern nicht weit entfernt sein).
Die Gebäudeswitche / Router sollten in zwei getrennten Räumen aufgestellt sein. Dies ist bei allen Standorten außer Favoritenstraße und ZID der Fall.
In allen Fällen ist der Router im gleichen Gehäuse wie der Switch untergebracht. Je nach verwendetem Modell handelt es sich dabei um eine gemeinsame Switching/Router Engine (ZID, Treitlstraße, Argentinierstraße, Gußhaus, Getreidemarkt) oder im Switch befindet sich ein zusätzliches Routing-Modul. In Falle des eigenen Moduls erfolgt geräteintern dann die Kommunikation über einen Gigabit-Bus. Dies stellt natürlich Kapazitätseinschränkungen dar, gleichzeitig gibt es dadurch aber auch zusätzliche Komponenten, die ausfallen können, und das Management und die Softwareoberfläche (unterschiedliche Betriebssysteme !) wird deutlich komplizierter. Bei manchen Standorten (maximal bei einem Gebäudeswitch pro Standort) gibt es aus Kapazitätsgründen (Anzahl der Ports) für den Switch noch eine Erweiterung mit einem externen Gigabit-Switch.
Die beiden Backboneswitche sind mit einem Gigabit Link verbunden. Damit kann z.B. bei den Geräten mit einem eigenen Routing-Modul bei dessen Ausfall das Routing vom zweiten Router übernommen werden. Ein wichtiges Kriterium ist auch, dass Module im Betrieb getauscht bzw. ein-/ausgebaut werden können.
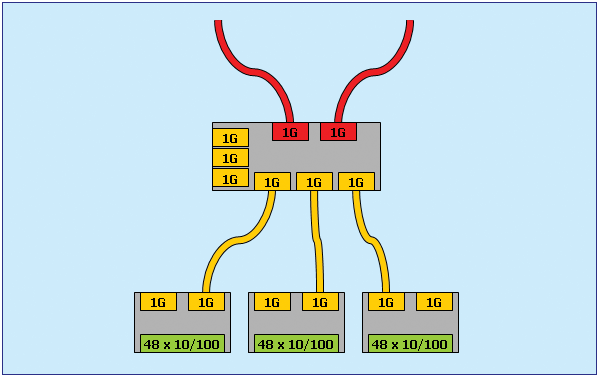
Ein Etagenswitch soll nun mit beiden Gebäudeswitchen über Gigabit verbunden sein, wobei mindestens eine Verbindung direkt erfolgen soll, die zweite kann auch über einen weiteren Etagenswitch erfolgen.
Die typische Struktur im Gebäude hat daher folgendes Aussehen:
Je nach der notwendigen Portanzahl wird die Realisierung aber unterschiedlich kompliziert, wie einige Musterkonfigurationen für den Standort Gußhaus zeigen:
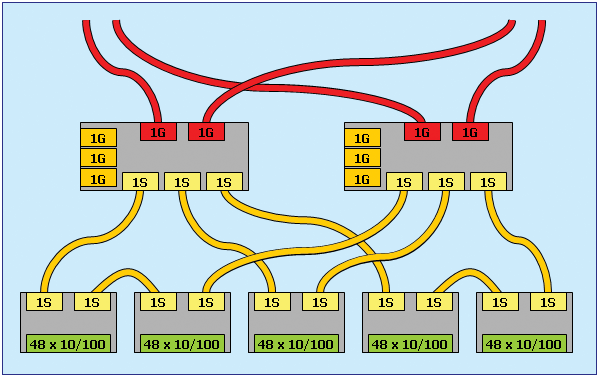
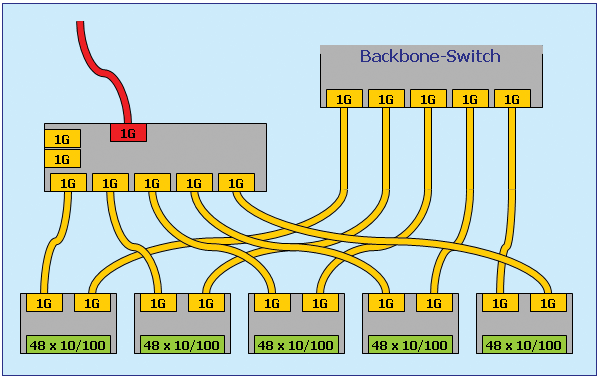
Durch den Spanning Tree Algorithmus gibt es aber Einschränkungen, wie viele Switche maximal zwischen zwei Endgeräten verwendet werden dürfen. Dadurch ist die Flexibilität der Zusammenschaltung von Etagen- switchen eingeschränkt.
Das Umschalten auf einen anderen verfügbaren Weg nach einem Ausfall der aktiven Verbindung dauert ca. 60 Sekunden.
Bei uns wird daher das Cisco-proprietäre Protokoll HSRP (Hot Standby Routing Protocol, RFC 2281) eingesetzt. Das Prinzip ist im Wesentlichen, dass jeder Router auf seinem Interface eine eigene IP-Adresse hat (bei uns in der Regel endend mit 125/126 bzw. 253/254). Diese Adresse wird vom Router beim Abschicken von Paketen verwendet. Zusätzlich wird von einem der beiden Router die "HSRP-Adresse" (z.B. 128.130.x.1) mit einer definierten Mac-Adresse (0000.0c07.ac**) emuliert. Welcher Router der aktive ist, machen sich die beiden Router untereinander auf Basis von Prioritäten in der Konfiguration aus. Wenn ein Router den anderen nicht mehr erreichen kann, so aktiviert er sich selber. Dies geschieht innerhalb ca. 10 Sekunden. Natürlich müssen dann die Etagen- Switche lernen, dass die Mac-Adresse des Default-Gateways jetzt über einen anderen Port erreichbar ist.
Ob das HSRP Protokoll für ein konkretes Subnetz eingesetzt wird, ist für den Benutzer nicht sofort ersichtlich. An Hand der Mac-Adresse des Default Gateways und z.B. durch auf den ersten Blick seltsam anmutende Ergebnisse beim Traceroute Befehl ist es erkennbar.
Es gibt in der Zwischenzeit auch ein Standard Protokoll, das Virtual Router Redundancy Protocol (VRRP) nach RFC 2338, das nach ähnlichen Prinzipien funktioniert, derzeit an der TU Wien im Backbone aber nicht eingesetzt wird.
Durch diese Maßnahmen stellen wir sicher, dass das Default Gateway immer (d.h. zumindest bei einem einfachen Fehler) erreichbar ist. Wenn ein Institut aber hinter einem institutseigenen Firewall liegt, der nicht ebenso redundant ausgeführt ist, bietet diese Redundanz leider nur eine beschränkte Hilfe.
Die beiden Core Switche mit integriertem Routing sind in zwei unterschiedlichen Gebäuden (Freihaus, Gußhaus) aufgestellt. Jeder der beiden Switche verfügt über zwei Netzteile, wobei eines davon über eine USV (Überbrückungszeit je nach Gebäude 30 Minuten bis 8 Stunden) versorgt wird (die im Freihaus im Notfall durch das Notstromaggregat des Hauses versorgt wird). Ein wichtiges Kriterium ist auch, dass Module im Betrieb getauscht bzw. ein-/ausgebaut werden können. Die Räume sind entsprechend klimatisiert und werden auch fernüberwacht (Strom, Temperatur, Feuchte, ...). Die beiden Core Switche sind untereinander mit derzeit einer Glasfaserstrecke verbunden.
Jeder Gebäudeswitch ist mit mindestens einem Core Switch verbunden, wobei jedes Gebäude mit jedem der beiden Core Switche mit einer direkten Glasfaserverbindung verbunden sein muss. Ob ein Gebäude mit 2, 3 oder 4 Verbindungen mit dem Core verfügt, hängt von der jeweiligen geografischen Lage und den verfügbaren Glasfaserwegen zwischen den Gebäuden ab. Für die Glasfaserstrecken werden, je nach Möglichkeit der Trassenführung und der Wegerechte, neben selbst verlegten Kabeln Strecken der Telekom Austria sowie der Memorex Telex Communications AG (MTCAG) eingesetzt. Dabei wird darauf geachtet, dass ein Gebäude möglichst über unterschiedliche Trassen zu den beiden Core Switchen geführt wird.
Diese Regel gilt naturgemäß nicht für "gebäudeübergreifende" VLANs, die für Institute benötigt werden, die das gleiche IP-Subnetz in mehreren Gebäuden nutzen wollen. Auch für Appletalk, Novell und DECnet trifft dies zu. In diesen Fällen ist also bei einer Störung mit längeren Auswirkungen zu rechnen.
Übrigens konnte die Umstellung von Layer 2 Core auf ein Layer 3 Core infolge der zu diesem Zeitpunkt existierenden redundanten Gebäuderouter ohne Betriebsunterbrechung durchgeführt werden.
An den Core Switches sind keine Endgeräte und auch keine Etagenswitche angeschlossen.
Das Routingprotocol hat nun einerseits die Aufgabe, mit den Nachbarroutern die vom eigenen Router direkt (connected) oder indirekt erreichbaren Subnetze auszutauschen, als auch, die Routingtabellen aufzubauen bzw. zu aktualisieren. Dabei müssen auch mehrere Wege unter Beachtung von Gewichten und Prioritäten berücksichtigt werden. An der TU Wien wird im Backbone das OSPF Protokoll (Open Shortest Path First) eingesetzt. Dies ist ein Routingprotocol, das hierarchisch basierend auf "Link States" mittels graphentheoretischer Algorithmen in jedem Router eine Sicht des kompletten Intranets errechnet und damit die Routingtabellen aktualisiert.
Wenn zu einem Ziel zwei Wege mit der gleichen Bewertung existieren, so wird automatisch eine Lastaufteilung erzielt. Gleichzeitig steht bei Ausfall eines der beiden Wege sofort ein zweiter Weg zur Verfügung und damit kann die Unterbrechung minimal gehalten werden. Dies ist auch einer der Gründe, warum die Gebäuderouter mit jeweils einem dedizierten Subnetz mit den Core-Routern verbunden sind. Sobald z.B. ein Interface ausgeschaltet wird (geplant oder wegen einer Störung), werden sofort alle Wege, die über dieses Interface gehen, im Router mit diesem Interface aus der Routingtabelle entfernt. Wenn noch eine zweite Route zu einem Ziel existiert hat, kann diese sofort (und jetzt alleinig) verwendet werden, und es findet praktisch keine Unterbrechung statt.
| von | nach | via | Maßnahme |
| PC/Ethernetkarte | Etagen Switch Port | TP-Kabel | Keine Ausfallsicherheit durch TUNET möglich. Siehe 3.1 |
| Etagen Switch | Gebäude Switch | Glasstrecke | Pro Gebäude 2 Backbone Switche. Je ein Weg zu jedem Gebäude Switch. Siehe 3.2 |
| Gebäude Switch | Gebäuderouter | Intern od. Glasstrecke | Pro Gebäude 2 Backbone Router. Siehe 3.3 |
| Gebäude Router/Switch | Core-Router | Glasstrecke | 2 Core Router auf der TU Wien. Je ein Weg zu jedem Gebäude Switch. Siehe 3.3 |
| Core Router | Gebäude Router/Switch ZID oder Karlsplatz | Glasstrecke | Pro Gebäude 2 Backbone Router + Switche. Siehe 3.3 |
| Gebäude Router/Switch | Etagen Switch | Glasstrecke | Nur bei Weg über ZID |
| Gebäude Switch oder Etagenswitch | Firewall | Kupfer | Zum inneren Interface des Firewalls. Jeweils ein Firewall im ZID und am Karlsplatz in einer Active/Standby Konfiguration |
| Firewall | Anbindungsswitch | Kupfer, 100 MBit/s | Je ein Anbindungsswitch pro Gebäude, untereinander verbunden. Kann Verkehr, wenn z.B. gebäudeeigener Firewall ausgefallen ist, zum anderen Gebäude leiten. |
| Anbindungsswitch | Anbindungsrouter |
Glaspatchung
|
Je ein Anbindungsrouter am ZID und am Karlsplatz. Hier wird entschieden,
wohin das Paket geschickt werden soll (ACOnet, Internet, Teleweb, Inode)
|
|
Anbindungsrouter
|
Anbindungsswitch | Glaspatchung | |
| Anbindungsswitch | AConet / Teleweb | Glasstrecke | |
| ACOnet Router | Internet | Glasstrecke |
Wie schon innerhalb der TU Wien dargestellt, kann der Rückweg infolge der alternativwege ein anderer sein. Der vereinfachte Ablauf ist auch in folgender Grafik dargestellt:
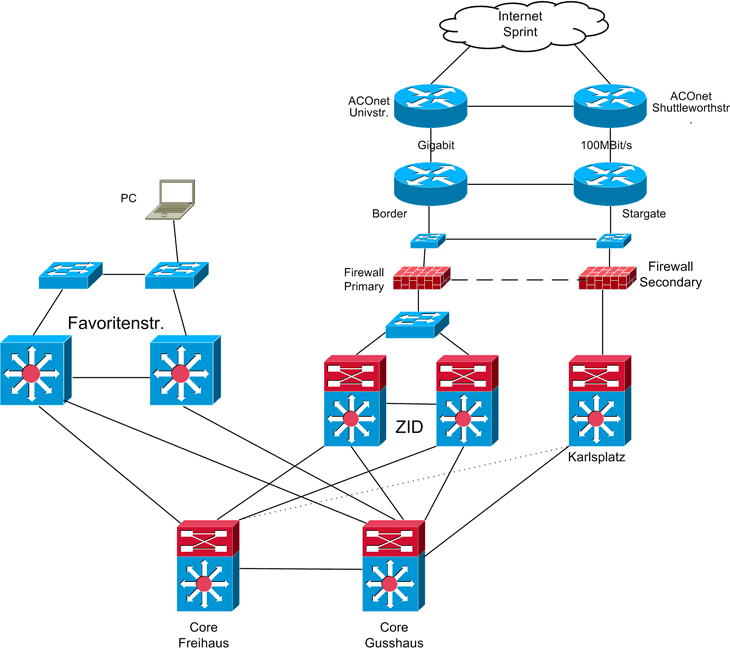
Redundante Server, wie externe Nameserver, Mail- Bastionsrechner sind in einer DMZ, die redundant an beide Firewalls angeschlossen sind, platziert (in der Grafik nicht dargestellt).
Wenn verfügbar, sind die Geräte der externen Anbindung mit zwei Stromversorgungen ausgestattet. Überall sind entsprechende USVs vorhanden (mindestens 4 Stunden Überbrückungszeit). Die Geräte sind alle gebäude- redundant (Freihaus / Karlsplatz) ausgeführt. Die Verbindungswege führen soweit wie möglich über unterschiedliche Trassen und sind zum Teil doppelt (zumindest logisch gesehen) ausgelegt.
Die Firewalls verwenden eine ähnliche Technik, wie bereits beim HSRP-Protokoll beschrieben, um dem aktiven Firewall immer die gleiche Mac-Adresse und IP-Adresse zu geben. Bei den externen Routern wird das BGP Protokoll (border Gateway Protocol) verwendet, das umfangreiche Möglichkeiten der Steuerung von redundanten Wegen zu Destinationen im Internet vorsieht.
Internet-Räume, Wählleitungszugänge, TU-ADSL, xDSL@student, Demonetz und WLAN werden über eine ähnliche Konstruktion mit einem eigenen Firewall-Paar zu den externen Routern geführt.
Bei Servern gibt es grundsätzlich 3 Ebenen, auf denen die Betriebssicherheit angegangen werden kann:
Vom Design des Nameservice handelt es sich um eine weltweit verteilte Datenbank (vermutlich die größte überhaupt) mit lokaler Cache Funktion. Pro Domain (z.B. tuwien.ac.at) müssen mindestens zwei Nameserver existieren, die möglichst auf Servern, die in unterschiedlichen Gebäuden, wenn möglich sogar Netzen bzw. Providern bzw. Kontinenten aufgestellt sind. Ein Client (Arbeitsplatzrechner) konfiguriert die lokalen Nameserver der jeweiligen Organisation (tunamea und tunameb an der TU Wien) mit deren IP-Adressen (der Name kann ja nicht ohne das Nameservice selber auf eine Adresse umgesetzt werden). Die Anfragen eines Client gehen daher immer zum lokalen Nameserver mittels des DOMAIN Protokolls (in der Regel wird die UDP-Variante verwendet). Dieser kann die Antwort auf Grund der Daten im Cache geben oder fragt einen anderen Nameserver (normalerweise bereits den richtigen Nameserver für die Domain) und gibt dann die Antwort.
Wenn ein Client in einer gewissen Zeit keine Antwort vom Nameserver bekommt, fragt er den nächsten konfigurierten Nameserver. Leider dauert dieser Umschaltvorgang relativ lange (und ist auch vom jeweiligen Betriebssystem am Client abhängig), sodass das Umschalten meistens vom Anwender bemerkt wird. Verzögerungen treten auch an Stellen auf, wo man es nicht ad hoc erwartet. So erfragen viele Server beim Login-Vorgang den Namen, der zu einer IP-Adresse gehört, um diesen Namen bei Security-Überprüfungen und für das Logging zu verwenden. Da dies auch über den Nameserver abgewickelt wird, treten damit hier Verzögerungen auf.
Für die Domain tuwien.ac.at gibt es innerhalb der TU Wien zwei Server (tunamea und tunameb), die im Freihaus und in der Favoritenstraße aufgestellt sind. Die Generierung der Konfigurationsfiles für den Nameserver aus der TUNET Datenbank erfolgt einmal am Tag auf einem anderen Server, auf dessen lokalen Nameserver die neuen Daten auch aktiviert werden. Von dort holen sich dann obige Nameserver die neuen Daten, Subdomain für Subdomain, über einen längeren Zeitraum. Ein direktes Aktivieren aller Nameserverdaten (da jede Domain ein eigenes File ist, sind diese Daten auf etwa 250 Files verteilt) würde eine Störung von 1-2 Minuten des Nameservice bewirken !
Für die Abfrage nach Daten der TU Wien von Nameservern in der weiten Welt stehen zwei eigene Nameserver (tunamec und tunamed) an den Standorten Freihaus und Karlsplatz (in der DMZ des Firewalls der TU Wien möglichst nahe am Anschluss zum Internet Provider). Auch hier werden die Daten am TUNET Datenbank Server generiert und lokal aktiviert.
Für das Nameservice für Domains der TU Wien ungleich tuwien.ac.at ("Fremddomains") werden zwei eigene Server (tunamee, tunamef) im Freihaus und am Karlsplatz eingesetzt. Hier erfolgt die Generierung nicht aus der TUNET Datenbank sondern wird per Hand in den Text-Files eingetragen. Bei Änderungen erfolgt dann ein Reload des jeweiligen Nameservers, da hier wegen der geringen Datenmengen nur eine minimale Unterbrechung auftritt. (Eine Zusammenlegung mit den externen Nameservern würde bei diesen aber eine lange Unterbrechung erfordern.)
Die Nameserver für die Domain ac.at sind neben Wien (mehrere Standorte) auch in Deutschland und den Niederlanden aufgestellt. Für das Nameservice von at kommen noch Standorte in USA und UK dazu.
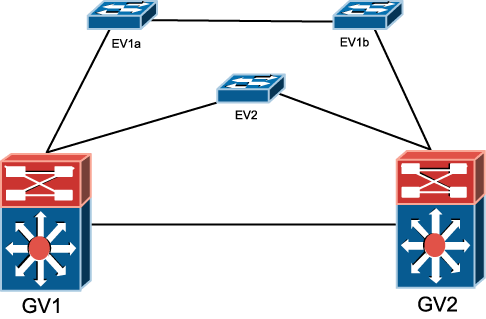
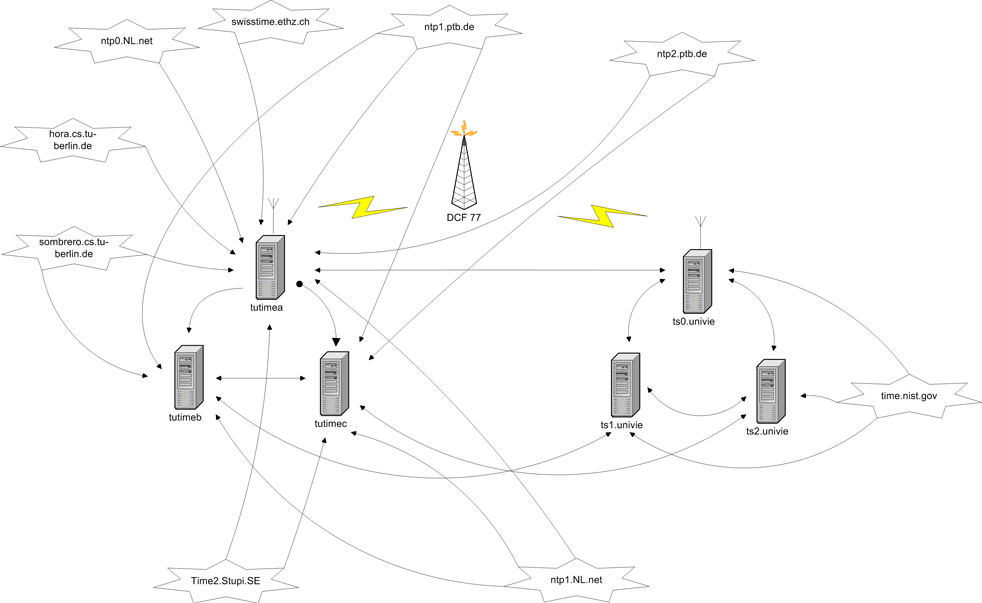
Auf der TU Wien sind drei Timeserver aufgestellt, zwei im Freihaus, einer in der Favoritenstraße. Einer der Timeserver im Freihaus erhält über eine Funkverbindung (Langwelle) Zeitsignale vom DCF77 Sender in Mainflingen bei Frankfurt, die auf Basis einer Atomuhr erzeugt werden.
Damit ein Client die Redundanz ausnutzen kann, müssen natürlich am Arbeitsplatzrechner mindestens zwei Server konfiguriert werden (siehe http://nic.tuwien.ac.at/services/time/).
Anbei eine Darstellung der derzeitigen Vernetzung unserer Timeserver.
Ähnlich wird bei den Mailbastionsrechnern, über die alle ankommende Mail (außer @tuwien.ac.at und @student. tuwien.ac.at) der TU Wien geführt wird, gearbeitet. Auf den externen (und nur dort) Nameservern ist für Mailrechner auf Basis der Eintragung in der TUNET Datenbank (Attribute MAIL/BASTION) eine Umleitung der Mails auf die beiden Bastionssysteme tuvok.kom.tuwien. ac.at und neelix.kom.tuwien.ac.at mittels MX-Records definiert. Diese Eintragungen haben beide die beste Priorität (0). Damit erfolgt automatisch eine Lastaufteilung (je nachdem, welchen der beiden Einträge der abschickende Rechner verwendet). Als dritter Eintrag sind der/die Rechner innerhalb der TU Wien mit einer schlechteren Priorität eingetragen. Für den Fall, dass beide Bastionsserver über längere Zeit gestört sind, kann daher per Hand auf den Firewalls die Sperre des SMTP-Port aufgehoben werden, und die Mails werden direkt an die Zielrechner an der TU Wien zugestellt. Dadurch entfallen naturgemäß die Schutzmaßnahmen gegen Mail-Relaying und Viren. Die beiden Bastionsrechner stehen im Freihaus und am Karlsplatz und sind in der DMZ der TU Wien angesiedelt.
Neben diesen Möglichkeiten verwenden die Mail Transfer Agents (das sind jene Programme, die für die Weiterleitung von Mails im Internet zuständig sind) den Mechanismus, dass eine Mail, die nicht sofort zugestellt werden kann, in einer Queue gehalten wird. Diese Queue wird dann z.B. in regelmäßigen Abständen abgearbeitet. Üblicherweise wird nach 4 Stunden Nichtzustellbarkeit der Absender darüber informiert (Warnung), es wird aber weiter versucht, die Mail zuzustellen. Erst nach 3-5 Tagen (je nach Konfiguration des MTA, an der TU Wien 5 Tage) wird aufgegeben, und die Mail wird als unzustellbar an den Absender zurückgewiesen.
Die Überprüfung auf Viren der Mails erfolgt über insgesamt 4 eigene Virenscanner, die auf drei Standorte der TU Wien verteilt sind. Einem Mailrouter bzw. Bastionsrechner sind ein bis zwei Virenscanner zugeordnet. Wenn keiner dieser Scanner erreichbar ist, wird der Absender mittels eines temporären Fehlercodes darüber informiert, sodass er einen anderen Mailrouter versuchen kann.
Anzumerken ist, dass bei von der TU Wien abgehender Mail (z. B. über die Server mr.tuwien.ac.at, pop. tuwien.ac.at, stud3.tuwien.ac.at) der Mechanismus der MX-Records nicht zur Anwendung kommen kann, da der "Outgoing SMTP Server" fix im Client (z. B. Eudora, Outlook Express, Netscape, ...) konfiguriert werden muss. Hier müssen dann Methoden, wie in 5.2 dargestellt, zur Verbesserung der Betriebssicherheit eingesetzt werden.
Im Frühjahr vorigen Jahres wurden mehrere Firmen zu einer Teststellung für einen Content Switch eingeladen. Dabei wurde an Hand einiger typischer Services (Protokolle) am ZID die Funktionalität der Testsysteme überprüft und entsprechend gegenübergestellt. Im Ergebnis fiel dann, nicht zuletzt auch wegen der Preisrelationen, die Entscheidung zu Gunsten der Content Switche der Firma Cisco Systems, konkret das Modell CSS 11503. Die Geräte wurden Ende 2002 geliefert und dann unterschiedliche Konfigurationen im Detail untersucht. Schrittweise werden nun alle Services der Abteilung Kommunikation mittels dieser Geräte redundant angeboten. Content Switche werden auch als ISO Layer 4-7 Switche bezeichnet.
In der folgenden Abbildung ist die logische Konfiguration des Content Switch dargestellt:
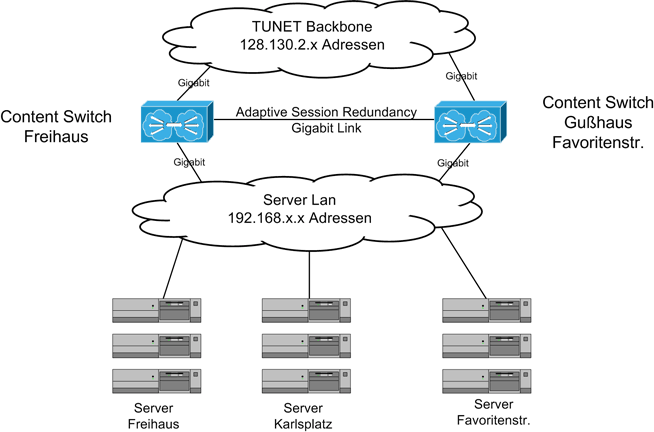
Ein Content Switch bietet eine Reihe von Möglichkeiten, die eine große Flexibilität ermöglichen:
Die Grenzen der Redundanz durch einen Content Switch und Verdopplung der Server sind bei Services, die Datenbestände im Hintergrund haben, wie z. B. die Web-Seiten beim Info-Server, die Mailboxen beim POP-Server und die TUNET-Datenbank. Hier sind dann wesentlich aufwändigere Konstruktionen zur gemeinsamen (redundanten) Datenhaltung erforderlich.
Auch die Chipkarten-Überprüfung ist wegen der komplexen verteilten Konfiguration der Anlage nicht redundant.
RFC 2281. Cisco Hot Standby Router Protocol (HSRP). T. Li, B. Cole, P. Morton, D. Li. (March 1998)
RFC 2338. Virtual Router Redundancy Protocol. S. Knight, D. Weaver, D. Whipple, R. Hinden, D. Mitzel, P. Hunt, P. Higginson, M. Shand, A. Lindem (April 1998)
RFC 2328. OSPF Version 2. J. Moy (April 1998)
DNS Resources Directory: http://www.dns.net/dnsrd
NTP: The Network Time Protocol: http://www.ntp.org/
RFC 2138, Remote Authentication Dial In User Service (RADIUS). C. Rigney, A. Rubens, W. Simpson, S. Willens (April 1997)
Ergänzung zum Entwurf aktive TUNET-Komponenten in den Institutsgebäuden der Technischen Universität Wien, Gußhausstraße 25 und 27-29. Manfred R. Siegl (August 2002).
Cisco LAN Switching. Kennedy Clark, Kevin Hamilton, Cisco Press (1999)
Building Cisco Multilayer Switched Networks. Karen Webb, Cisco Press (2000)
Interconnections: Bridges and Routers. Radia Perlman, Addison Wesley (1993)
Cisco TCP/IP Routing Professional Reference. Chris Lewis, McGraw-Hill (1998)
Routing in the Internet. Christian Huitema, Prentice Hall PTR (1995)
Online-Dokumentationsseiten des Herstellers
Cisco System, CCO : http://www.cisco.com/
 Seitenanfang | ZIDline 8 - Juni 2003 | ZID | TU Wien
Seitenanfang | ZIDline 8 - Juni 2003 | ZID | TU Wien